我们从自回归模型开始研究生成式建模。如前所述,我们假设我们可以访问由 n 维数据点 \(\mathbf{x}\) 组成的数据集 \(\mathcal{D}\)。为简单起见,我们假设数据点是二进制的,即 \(\mathbf{x} \in \{0,1\}^n\)。
解释:自回归模型是一类生成式模型,它使用数据自身的历史信息来预测未来的数据。在这种模型中,每个变量的概率分布依赖于之前的变量。这里我们处理的是二进制数据,即每个数据点的每个维度只能是0或1。
根据概率的链式法则,我们可以将 n 维的联合分布分解为:
\[p(\mathbf{x}) = \prod\limits_{i=1}^{n}p(x_i \vert x_1, x_2, \ldots, x_{i-1}) = \prod\limits_{i=1}^{n} p(x_i \vert \mathbf{x}_{< i } )\]
其中 \(\mathbf{x}_{< i}=[x_1, x_2, \ldots, x_{i-1}]\) 表示索引小于 i 的随机变量向量。
解释:链式法则是概率论中的基本原理,它允许我们将联合概率分解为条件概率的乘积。在这个公式中,我们将数据点 \(\mathbf{x}\) 的概率分解为每个维度 \(x_i\) 在已知前面所有维度 \(x_1\) 到 \(x_{i-1}\) 的条件下的概率乘积。这种分解方式是自回归模型的核心。
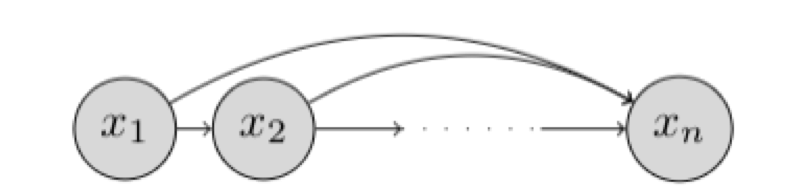
链式法则分解可以用贝叶斯网络图形化表示。
没有条件独立性假设的自回归贝叶斯网络的图形模型。
解释:贝叶斯网络是一种用有向无环图表示随机变量之间依赖关系的概率图模型。在这个图中,每个节点代表一个随机变量,箭头表示条件依赖关系。自回归模型中,每个变量都依赖于它前面的所有变量。
这种不做任何条件独立性假设的贝叶斯网络被称为遵循"自回归"属性。"自回归"一词源于时间序列模型文献,其中前几个时间步的观测值用于预测当前时间步的值。在这里,我们固定变量 \(x_1, x_2, \ldots, x_n\) 的顺序,第 i 个随机变量的分布取决于所选顺序中所有前面随机变量 \(x_1, x_2, \ldots, x_{i-1}\) 的值。
解释:自回归(Autoregressive)这个术语来源于时间序列分析,"auto"意味着"自己","regressive"意味着"回归",合起来就是"自我回归",表示当前值依赖于自己过去的值。在这种模型中,我们选择一个特定的变量顺序,每个变量的概率分布都依赖于在这个顺序中排在它前面的所有变量。
如果我们允许每个条件 \(p(x_i \vert \mathbf{x}_{< i})\) 以表格形式指定,那么这种表示是完全通用的,可以表示 n 个随机变量上的任何可能分布。然而,这种表示的空间复杂度随 n 呈指数增长。
解释:表格形式指定意味着为每种可能的输入组合列出对应的概率值。这种方法理论上可以表示任何分布,但实际上不可行,因为参数数量会随着维度呈指数增长。
为了理解原因,让我们考虑最后一个维度的条件概率 \(p(x_n \vert \mathbf{x}_{< n})\)。为了完全指定这个条件概率,我们需要为变量 \(x_1, x_2, \ldots, x_{n-1}\) 的 \(2^{n-1}\) 种配置指定概率。由于概率总和应为1,指定这个条件概率的参数总数为 \(2^{n-1} - 1\)。因此,对于通过链式法则分解的联合分布,条件概率的表格表示在实践中是不可行的。
解释:对于二进制变量,前 n-1 个变量有 \(2^{n-1}\) 种可能的组合。对于每种组合,我们需要指定 \(x_n=1\) 的概率(\(x_n=0\) 的概率就是1减去这个值)。因此总共需要 \(2^{n-1}\) 个参数。由于概率和为1的约束,实际上是 \(2^{n-1}-1\) 个自由参数。这个数量随 n 增长非常快,使得完整表格表示在实际中不可行。
在"自回归生成模型"中,条件概率被指定为具有固定参数数量的参数化函数。也就是说,我们假设条件分布 \(p(x_i \vert \mathbf{x}_{< i})\) 对应于伯努利随机变量,并学习一个函数,将前面的随机变量 \(x_1, x_2, \ldots, x_{i-1}\) 映射到这个分布的均值。因此,我们有:
\[p_{\theta_i}(x_i \vert \mathbf{x}_{< i}) = \mathrm{Bern}(f_i(x_1, x_2, \ldots, x_{i-1}))\]
其中 \(\theta_i\) 表示用于指定均值函数 \(f_i: \{0,1\}^{i-1}\rightarrow [0,1]\) 的参数集。
解释:伯努利分布(Bernoulli distribution)是一种描述二元随机事件的概率分布,如硬币翻转。它由一个参数 p 确定,表示事件发生(得到1)的概率。在自回归模型中,我们使用函数 \(f_i\) 来计算 \(x_i=1\) 的概率,这个函数的输入是前面所有的变量 \(x_1\) 到 \(x_{i-1}\)。
自回归生成模型的参数数量由 \(\sum_{i=1}^n \vert \theta_i \vert\) 给出。正如我们将在下面的例子中看到的,参数数量比之前考虑的表格设置少得多。然而,与表格设置不同,自回归生成模型不能表示所有可能的分布。其表达能力受到限制,因为我们将条件分布限制为对应于伯努利随机变量,其均值通过受限类的参数化函数指定。
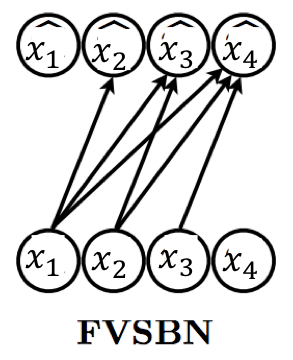
四个变量上的全可见sigmoid信念网络。条件概率分别由 \(\widehat{x}_1, \widehat{x}_2, \widehat{x}_3, \widehat{x}_4\) 表示。
解释:全可见sigmoid信念网络(Fully Visible Sigmoid Belief Network, FVSBN)是一种自回归模型,其中每个条件概率分布由sigmoid函数参数化。在图中,每个节点 \(\widehat{x}_i\) 表示对应变量 \(x_i\) 的条件概率分布。
在最简单的情况下,我们可以将函数指定为输入元素的线性组合,然后通过sigmoid非线性(将输出限制在0和1之间)。这给我们提供了"全可见sigmoid信念网络"(FVSBN)的公式。
\[f_i(x_1, x_2, \ldots, x_{i-1}) =\sigma(\alpha^{(i)}_0 + \alpha^{(i)}_1 x_1 + \ldots + \alpha^{(i)}_{i-1} x_{i-1})\]
其中 \(\sigma\) 表示sigmoid函数,\(\theta_i=\{\alpha^{(i)}_0,\alpha^{(i)}_1, \ldots, \alpha^{(i)}_{i-1}\}\) 表示均值函数的参数。变量 i 的条件概率需要 i 个参数,因此模型中的参数总数由 \(\sum_{i=1}^ni= O(n^2)\) 给出。请注意,参数数量比表格情况的指数复杂度少得多。
解释:sigmoid函数 \(\sigma(x) = \frac{1}{1+e^{-x}}\) 是一种将任意实数映射到(0,1)区间的函数,常用于将线性组合转换为概率值。在FVSBN中,每个条件概率是前面所有变量的线性组合通过sigmoid函数得到的。第i个变量的条件概率需要i个参数(一个偏置项 \(\alpha^{(i)}_0\) 和 i-1 个权重 \(\alpha^{(i)}_1, \ldots, \alpha^{(i)}_{i-1}\))。总参数数量是 \(\sum_{i=1}^n i = \frac{n(n+1)}{2} = O(n^2)\),这比表格表示的 \(O(2^n)\) 小得多。
增加自回归生成模型表达能力的自然方法是为均值函数使用更灵活的参数化,例如多层感知机(MLP)。例如,考虑具有1个隐藏层的神经网络。变量 i 的均值函数可以表示为:
\[\mathbf{h}_i = \sigma(A_i \mathbf{x_{< i}} + \mathbf{c}_i)\\ f_i(x_1, x_2, \ldots, x_{i-1}) =\sigma(\boldsymbol{\alpha}^{(i)}\mathbf{h}_i +b_i )\]
其中 \(\mathbf{h}_i \in \mathbb{R}^d\) 表示MLP的隐藏层激活,\(\theta_i = \{A_i \in \mathbb{R}^{d\times (i-1)}, \mathbf{c}_i \in \mathbb{R}^d, \boldsymbol{\alpha}^{(i)}\in \mathbb{R}^d, b_i \in \mathbb{R}\}\) 是均值函数 \(\mu_i(\cdot)\) 的参数集。这个模型中的参数总数由矩阵 \(A_i\) 主导,为 \(O(n^2 d)\)。
解释:多层感知机(MLP)是一种前馈神经网络,由多层神经元组成,可以学习更复杂的函数。在这个例子中,我们使用一个隐藏层的MLP来参数化条件概率。\(\mathbf{h}_i\) 是隐藏层的激活值,它是前面所有变量的线性组合通过sigmoid函数得到的。然后,条件概率是隐藏层激活值的另一个线性组合通过sigmoid函数得到的。这种方法的参数数量是 \(O(n^2d)\),其中d是隐藏层的大小。
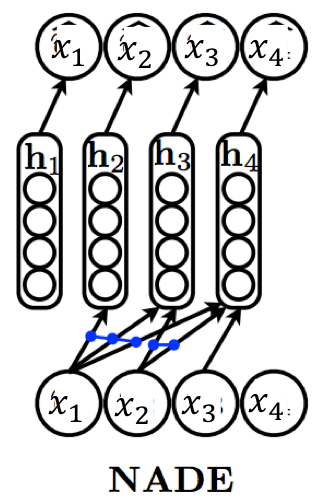
四个变量上的神经自回归密度估计器。条件概率分别由 \(\widehat{x}_1, \widehat{x}_2, \widehat{x}_3, \widehat{x}_4\) 表示。蓝色连接表示用于计算隐藏层激活的绑定权重 \(W[., i]\)。
解释:神经自回归密度估计器(Neural Autoregressive Density Estimator, NADE)是一种改进的自回归模型,它通过参数共享提高了统计和计算效率。在图中,蓝色连接表示共享权重,这些权重用于计算不同条件概率的隐藏层激活。
"神经自回归密度估计器"(NADE)提供了另一种基于MLP的参数化,比普通方法在统计和计算上更有效。在NADE中,用于评估条件概率的函数之间共享参数。特别是,隐藏层激活被指定为:
\[\mathbf{h}_i = \sigma(W_{., < i} \mathbf{x_{< i}} + \mathbf{c})\\ f_i(x_1, x_2, \ldots, x_{i-1}) =\sigma(\boldsymbol{\alpha}^{(i)}\mathbf{h}_i +b_i )\]
其中 \(\theta=\{W\in \mathbb{R}^{d\times n}, \mathbf{c} \in \mathbb{R}^d, \{\boldsymbol{\alpha}^{(i)}\in \mathbb{R}^d\}^n_{i=1}, \{b_i \in \mathbb{R}\}^n_{i=1}\}\) 是均值函数 \(f_1(\cdot), f_2(\cdot), \ldots, f_n(\cdot)\) 的完整参数集。权重矩阵 \(W\) 和偏置向量 \(\mathbf{c}\) 在条件概率之间共享。共享参数提供两个好处:
\[\mathbf{h}_i = \sigma(\mathbf{a}_i)\\ \mathbf{a}_{i+1} = \mathbf{a}_{i} + W[., i]x_i\]
基本情况由 \(\mathbf{a}_1=\mathbf{c}\) 给出。
解释:NADE通过在不同条件概率之间共享参数来提高效率。所有条件概率使用同一个权重矩阵W和偏置向量c,只有输出层的参数 \(\boldsymbol{\alpha}^{(i)}\) 和 \(b_i\) 是不同的。这将参数数量从 \(O(n^2d)\) 减少到 \(O(nd)\)。
此外,NADE使用递归计算隐藏层激活,避免了重复计算。当计算 \(\mathbf{h}_{i+1}\) 时,我们可以利用 \(\mathbf{h}_i\) 的计算结果,只需加上新项 \(W[., i]x_i\)。这使得计算所有条件概率的时间复杂度为 \(O(nd)\),而不是 \(O(n^2d)\)。
RNADE算法扩展了NADE,以学习对实值数据的生成模型。在这里,条件概率通过连续分布建模,例如K个高斯分布的等权重混合。我们不是学习均值函数,而是学习每个条件概率的K个高斯分布的均值 \(\mu_{i,1}, \mu_{i,2},\ldots, \mu_{i,K}\) 和方差 \(\Sigma_{i,1}, \Sigma_{i,2},\ldots, \Sigma_{i,K}\)。为了统计和计算效率,单个函数 \(g_i: \mathbb{R}^{i-1}\rightarrow\mathbb{R}^{2K}\) 输出第i个条件分布的K个高斯分布的所有均值和方差。
解释:RNADE(Real-valued Neural Autoregressive Density Estimator)是NADE的扩展,用于处理实值数据而不是二进制数据。它使用高斯混合模型(Gaussian Mixture Model, GMM)来表示每个条件概率分布。高斯混合模型是多个高斯分布的加权和,可以表示更复杂的分布。在RNADE中,每个条件概率是K个高斯分布的等权重混合,需要学习每个高斯分布的均值和方差。
请注意,NADE需要指定变量的单一固定顺序。顺序的选择可能导致不同的模型。EoNADE算法允许训练具有不同顺序的NADE模型集合。
解释:在自回归模型中,变量的顺序会影响模型的性能,因为不同的顺序会导致不同的条件概率分解。EoNADE(Ensemble of NADEs)通过训练多个使用不同变量顺序的NADE模型,然后将它们组合起来,以减少对特定顺序的依赖。
回想一下,学习生成模型涉及优化数据分布和模型分布之间的接近程度。一种常用的接近度量是数据分布和模型分布之间的KL散度。
\[\min_{\theta\in \mathcal{M}}d_{KL} (p_{\mathrm{data}}, p_{\theta}) = \mathbb{E}_{\mathbf{x} \sim p_{\mathrm{data}} }\left[\log p_{\mathrm{data}}(\mathbf{x}) - \log p_{\theta}(\mathbf{x})\right]\]
解释:KL散度(Kullback-Leibler散度)是衡量两个概率分布差异的度量。在生成模型中,我们希望模型分布 \(p_{\theta}\) 尽可能接近真实数据分布 \(p_{\mathrm{data}}\)。KL散度 \(d_{KL}(p_{\mathrm{data}}, p_{\theta})\) 衡量从 \(p_{\mathrm{data}}\) 到 \(p_{\theta}\) 的信息损失,值越小表示两个分布越接近。
在继续之前,我们对KL散度做两点说明。首先,我们注意到任何两个分布之间的KL散度是不对称的。当我们浏览本章时,鼓励读者思考如果我们决定优化反向KL散度会出现什么问题。其次,KL散度严重惩罚任何为 \(p_{\mathrm{data}}\) 下可能采样的数据点分配低概率的模型分布 \(p_\theta\)。在极端情况下,如果密度 \(p_\theta(\mathbf{x})\) 对从 \(p_{\mathrm{data}}\) 采样的数据点评估为零,目标函数评估为 \(+\infty\)。
解释:KL散度的不对称性意味着 \(d_{KL}(p_{\mathrm{data}}, p_{\theta}) \neq d_{KL}(p_{\theta}, p_{\mathrm{data}})\)。我们选择最小化 \(d_{KL}(p_{\mathrm{data}}, p_{\theta})\) 而不是 \(d_{KL}(p_{\theta}, p_{\mathrm{data}})\),这两种选择会导致不同的优化行为。
前向KL散度 \(d_{KL}(p_{\mathrm{data}}, p_{\theta})\) 在 \(p_{\mathrm{data}}(\mathbf{x}) > 0\) 但 \(p_{\theta}(\mathbf{x}) \approx 0\) 时会产生非常大的惩罚,因为 \(\log \frac{p_{\mathrm{data}}(\mathbf{x})}{p_{\theta}(\mathbf{x})} \to \infty\)。这意味着模型必须为数据分布中的所有点分配一定的概率,导致"覆盖"行为。
反向KL散度 \(d_{KL}(p_{\theta}, p_{\mathrm{data}})\) 在 \(p_{\theta}(\mathbf{x}) > 0\) 但 \(p_{\mathrm{data}}(\mathbf{x}) \approx 0\) 时会产生大的惩罚,导致"模式寻找"行为,模型可能只捕获数据分布的一部分模式。
由于 \(p_{\mathrm{data}}\) 不依赖于 \(\theta\),我们可以等价地通过最大似然估计恢复最优参数。
\[\max_{\theta\in \mathcal{M}}\mathbb{E}_{\mathbf{x} \sim p_{\mathrm{data}} }\left[\log p_{\theta}(\mathbf{x})\right].\]
这里,\(\log p_{\theta}(\mathbf{x})\) 被称为数据点 \(\mathbf{x}\) 相对于模型分布 \(p_\theta\) 的对数似然。
解释:最大似然估计(Maximum Likelihood Estimation, MLE)是一种常用的参数估计方法,它选择使观测数据概率最大的参数值。在生成模型中,我们希望找到使数据集中的样本在模型下概率最大的参数 \(\theta\)。
最小化KL散度 \(d_{KL}(p_{\mathrm{data}}, p_{\theta})\) 等价于最大化期望对数似然 \(\mathbb{E}_{\mathbf{x} \sim p_{\mathrm{data}} }[\log p_{\theta}(\mathbf{x})]\),因为 \(\log p_{\mathrm{data}}(\mathbf{x})\) 不依赖于 \(\theta\)。
为了近似未知 \(p_{\mathrm{data}}\) 的期望,我们做一个假设:数据集 \(\mathcal{D}\) 中的点是从 \(p_{\mathrm{data}}\) 独立同分布采样的。这允许我们获得目标函数的无偏蒙特卡洛估计:
\[\max_{\theta\in \mathcal{M}}\frac{1}{\vert D \vert} \sum_{\mathbf{x} \in\mathcal{D} }\log p_{\theta}(\mathbf{x}) = \mathcal{L}(\theta \vert \mathcal{D}).\]
解释:由于我们不知道真实的数据分布 \(p_{\mathrm{data}}\),我们使用数据集 \(\mathcal{D}\) 中的样本来近似期望。假设数据集中的样本是从 \(p_{\mathrm{data}}\) 独立同分布(i.i.d.)采样的,我们可以用样本平均值来近似期望,得到最大似然目标函数 \(\mathcal{L}(\theta \vert \mathcal{D})\)。
最大似然估计(MLE)目标有一个直观的解释:选择模型参数 \(\theta \in \mathcal{M}\),使 \(\mathcal{D}\) 中观察到的数据点的对数概率最大化。
解释:最大似然估计的直观解释是:选择能够最好地解释观测数据的模型参数。在生成模型中,这意味着选择使数据集中的样本在模型下概率最大的参数。
在实践中,我们使用小批量梯度上升优化MLE目标。该算法分迭代进行。在每次迭代 t,我们从数据集中随机采样一个小批量 \(\mathcal{B}_t\) 的数据点(\(\vert \mathcal{B}_t\vert < \vert \mathcal{D} \vert\)),并计算小批量目标函数的梯度。迭代 t+1 的参数通过以下更新规则给出:
\[\theta^{(t+1)} = \theta^{(t)} + r_t \nabla_\theta\mathcal{L}(\theta^{(t)} \vert \mathcal{B}_t)\]
其中 \(\theta^{(t+1)}\) 和 \(\theta^{(t)}\) 分别是迭代 t+1 和 t 的参数,\(r_t\) 是迭代 t 的学习率。通常,我们只指定初始学习率 \(r_1\) 并根据计划更新学习率。随机梯度上升的变体,如RMS prop和Adam,采用稍微更好的更新规则。
解释:小批量梯度上升(Mini-batch Gradient Ascent)是一种优化算法,它使用数据的小批量来估计梯度,然后沿梯度方向更新参数。这比使用整个数据集计算梯度更高效,特别是对于大型数据集。
在每次迭代中,我们从数据集中随机采样一个小批量 \(\mathcal{B}_t\),计算目标函数关于当前参数的梯度 \(\nabla_\theta\mathcal{L}(\theta^{(t)} \vert \mathcal{B}_t)\),然后沿梯度方向更新参数,步长由学习率 \(r_t\) 控制。
实践中常用的优化算法如RMSprop和Adam是随机梯度下降/上升的改进版本,它们通过自适应调整每个参数的学习率来加速收敛。
从实际角度来看,我们必须考虑如何选择超参数(如初始学习率)和梯度下降的停止标准。对于这两个问题,我们遵循机器学习中的标准做法,监控验证数据集上的目标函数。因此,我们选择在验证数据集上表现最好的超参数,并在验证对数似然不再改善时停止更新参数[1]。
解释:在训练机器学习模型时,我们通常将数据分为训练集、验证集和测试集。训练集用于学习模型参数,验证集用于调整超参数和确定何时停止训练,测试集用于评估最终模型的性能。
早停(Early Stopping)是一种正则化技术,当验证集上的性能不再改善时停止训练,以防止过拟合。在这里,我们监控验证集上的对数似然,当它不再增加时停止训练。
现在我们有了明确定义的目标和优化程序,唯一剩下的任务是在自回归生成模型的上下文中评估目标。为此,我们将自回归模型的分解联合分布代入MLE目标,得到:
\[\max_{\theta \in \mathcal{M}}\frac{1}{\vert D \vert} \sum_{\mathbf{x} \in\mathcal{D} }\sum_{i=1}^n\log p_{\theta_i}(x_i \vert \mathbf{x}_{< i})\]
其中 \(\theta = \{\theta_1, \theta_2, \ldots, \theta_n\}\) 现在表示条件概率的集体参数集。
解释:将自回归模型的联合分布分解代入最大似然目标,我们得到一个关于条件概率对数的和。这意味着我们可以独立地优化每个条件概率分布的参数,这简化了学习过程。
自回归模型中的推断很简单。对于任意点 \(\mathbf{x}\) 的密度估计,我们只需评估每个 i 的对数条件概率 \(\log p_{\theta_i}(x_i \vert \mathbf{x}_{< i})\),并将它们相加得到模型对 \(\mathbf{x}\) 的对数似然。由于我们知道条件向量 \(\mathbf{x}\),每个条件概率可以并行计算。因此,密度估计在现代硬件上是高效的。
解释:推断(Inference)是指使用训练好的模型对新数据进行预测或评估的过程。在自回归模型中,计算一个数据点的概率(密度估计)非常直接:我们只需计算每个维度的条件概率,然后将它们相乘(或者将对数概率相加)。由于所有条件概率都依赖于已知的数据点 \(\mathbf{x}\),它们可以并行计算,这在现代GPU等并行计算硬件上非常高效。
从自回归模型采样是一个顺序过程。这里,我们首先采样 \(x_1\),然后在已采样的 \(x_1\) 条件下采样 \(x_2\),接着在 \(x_1\) 和 \(x_2\) 条件下采样 \(x_3\),依此类推,直到在之前采样的 \(\mathbf{x}_{< n}\) 条件下采样 \(x_n\)。对于需要实时生成高维数据的应用,如音频合成,顺序采样可能是一个昂贵的过程。在本课程的后面,我们将讨论并行Wavenet如何绕过这种昂贵的采样过程。
解释:从生成模型中采样(Sampling)是指生成新的数据点的过程。在自回归模型中,采样必须按顺序进行:先生成第一个维度,然后基于第一个维度生成第二个维度,以此类推。这种顺序依赖性使得采样过程在高维数据(如音频、图像)中可能变得计算密集。并行Wavenet是一种技术,它通过训练一个"学生"模型来模拟已训练的自回归"教师"模型,从而实现并行采样。
最后,自回归模型不直接学习数据的无监督表示。在接下来的几节课中,我们将研究潜变量模型(例如,变分自编码器),它们显式地学习数据的潜在表示。
解释:自回归模型专注于建模数据的联合概率分布,但不直接学习数据的低维表示或特征。潜变量模型(Latent Variable Models)如变分自编码器(Variational Autoencoders, VAEs)则明确地学习数据的低维潜在表示,这些表示可以捕获数据的语义特征,并用于生成新数据或进行下游任务。
1 鉴于此类问题的非凸性质,优化程序可能会陷入局部最优。因此,早停通常不是最优的,但是一种非常实用的策略。
解释:非凸优化问题(Non-convex Optimization)是指目标函数具有多个局部最小值或最大值的优化问题。深度学习中的大多数优化问题都是非凸的,这意味着优化算法可能会收敛到局部最优解而不是全局最优解。早停是一种实用的策略,它在验证性能开始下降时停止训练,以防止过拟合,但它可能会导致模型停留在局部最优解。